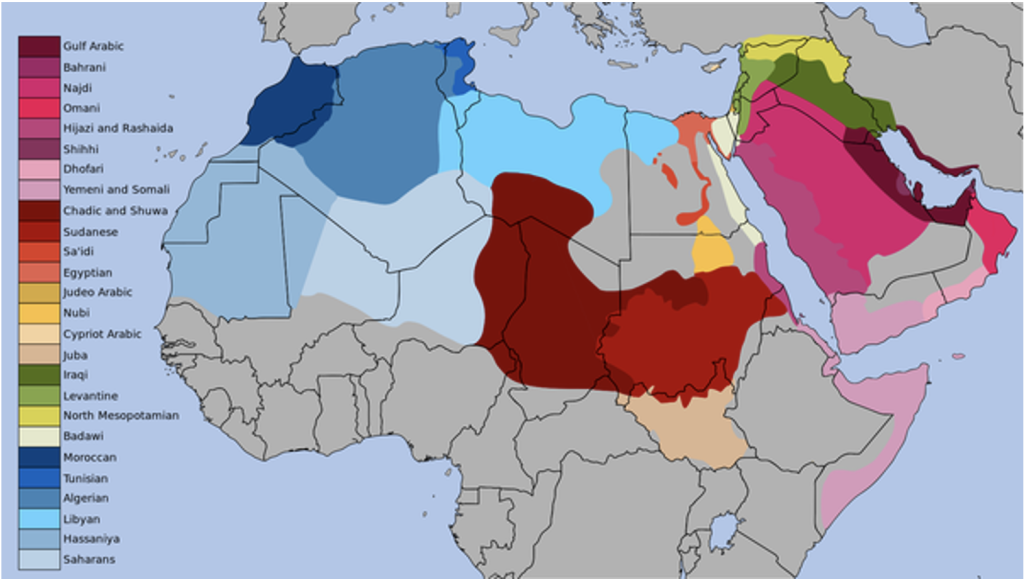
Arabic is spoken by millions of people worldwide, and it is estimated that there are over 420 million native speakers of Arabic, spread across various regions and countries. Arabic is known for its fascinating linguistic landscape, characterized by a wide variety of dialects. These dialects differ significantly from one another, both in terms of pronunciation and vocabulary.
The Arabic project, led by Dr. Samantha Wray from Dartmouth College, in collaboration with Dr. Suhail Matar from NYU, focuses on the study of Arabic language and its unique features. By exploring the morphology, syntax, and processing of Arabic, we aim to contribute to our understanding of this language.
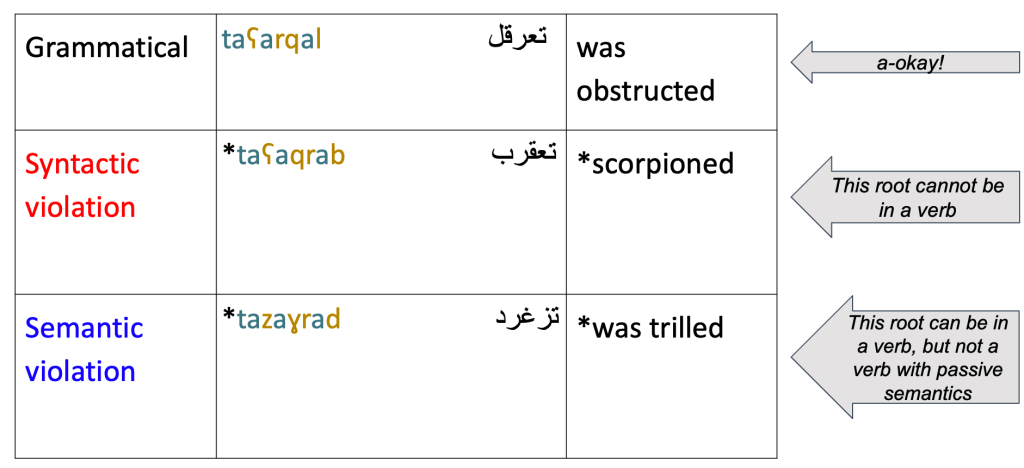
Arabic words are formed through the interleaving of two discontinuous bound morphemes: the root and the pattern. The root encodes the broad, core semantic meaning, while the pattern or template encodes syntactic and semantic information such as part of speech, number, person, and case.
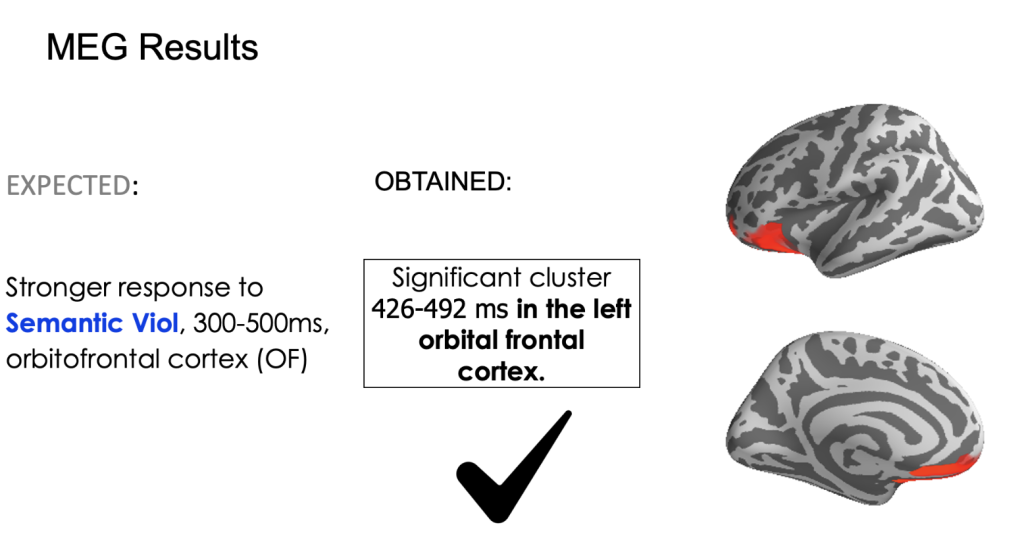
The study of Arabic has significantly advanced our previous knowledge. Preliminary MEG results have revealed activation associated with the difference in syntactic and semantic violation in the left orbito-frontal cortex, which is consistent with findings from previous cross-linguistic research. This suggests that the brain is sensitive to the syntactic and semantic properties of sub-word parts, even when those parts cannot stand alone.
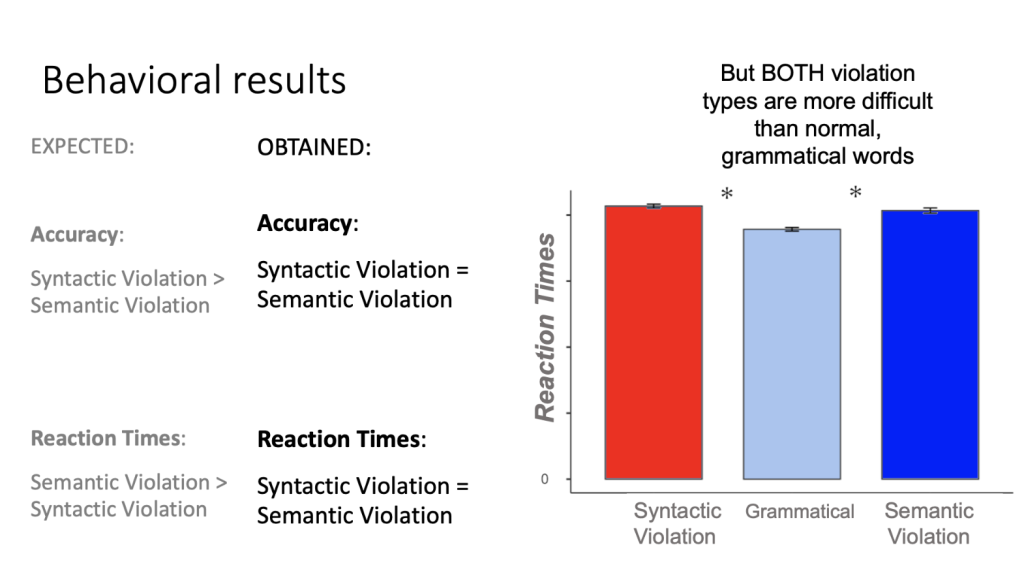
However, behavioral and brain data show some divergence. Syntactic and semantic violation words are recognized at the same speed and with the same level of accuracy. This raises an intriguing question: Can the root+pattern system of Arabic allow for the meaning of a novel word to be more easily coerced by the reader?
We aim to explore this question to gain deeper insights into the unique characteristics of the Arabic language. The root+pattern system enables the formation of words with distinct meanings by combining roots and patterns. This system potentially provides a mechanism for the reader to more easily infer the meaning of a novel word based on the familiar root and pattern combination.
For more information about the Arabic project, you can read our SNL poster here.