Bangla (also known as Bengali) is an Indo-Aryan language native to the Bengal region of South Asia. It serves as the official language of West Bengal in India and is the national language of Bangladesh. With approximately 300 million native speakers, Bangla ranks as the 6th most spoken language in the world. One of the distinctive features of Bangla is its writing system, which belongs to the Brahmic scripts category known as an Abugida. This writing system uses a set of characters that represent consonant-vowel combinations, reflecting the phonetic nature of the language.
The Business Standard 2022, Languages of Bangladesh, TBS Report <https://www.tbsnews.net/supplement/languages-bangladesh-373636>.
Bangla is morphologically rich and highly inflected. The language employs both prefixation and suffixation for morphological derivation, allowing for the creation of complex words with nuanced meanings. For instance, the word যোগ (jog) meaning ‘auspicious time’ can be transformed through morphological derivation into প্রতিযোগ (prôtijog) meaning ‘hostility,’ and further into প্রতিযোগিতা (prôtijogita) meaning ‘competition.’
In addition to its rich morphology, Bangla exhibits a semi-shallow orthography, fostering a close one-to-one correspondence between sounds (phonemes) and letters (graphemes) in most cases. This characteristic enhances the accessibility of written texts and aids language learners in associating spoken and written forms effectively.
Despite its linguistic richness and complexity, Bangla has received limited attention in neuroscience studies, particularly in the domain of morphological processing. While there exists one EEG study on speech perception in the language, there are no known neuroimaging studies on derivational morphology or other aspects of morphological processing in Bangla. The scarcity of neuroscientific research on Bangla underscores the need for further exploration in this field. Studying the neural underpinnings of morphological processing and other linguistic phenomena in Bangla will not only enhance our understanding of the language itself but also contribute to broader research on the neuroscience of language, offering insights into the processing mechanisms across diverse linguistic structures and language families.
The Bangla project is led by Dr. Dustin Alfonso Chacón (University of Georgia) in collaboration with Swarnendu Moitra. In our study on Bangla, we investigated the prefix attachment rules in the language. Specifically, we examined the prefixes prôti- and duḥ-, which are known to attach to nouns with abstract senses. The prefix prôti- (প্রতি) conveys the meaning of ‘opposite’ or ‘reversal’ of the noun it attaches to, akin to the English prefixes “anti-” or “trans-“. On the other hand, the prefix duḥ- (দুঃ) implies a negative affect towards the noun, indicating something ‘bad’ in relation to the noun.
In our experimental design, we employed both categorical violation (CatViol) and semantic violation (SemViol) paradigms to explore how these prefixes fit within the SAVANT model. By manipulating these prefix attachment rules and observing participants’ responses, we aimed to gain deeper insights into the morphological processing of Bangla and how the brain handles the complex interactions between these prefixes and the abstract noun stems.

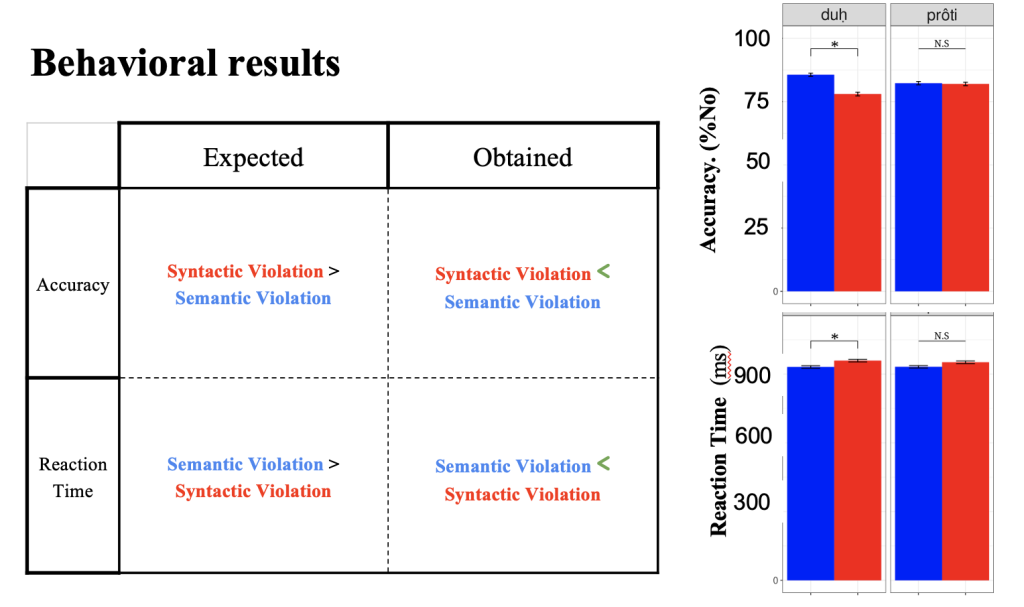
Through our behavioral data analysis, we have confirmed the distinction between the processing of syntactic and semantic information in word formation, shedding light on the unique morphological characteristics of the language. Interestingly, our findings revealed a pattern that is the reverse of what was previously observed in the literature, with semantic violations being easier to process than syntactic violations.
Moreover, our preliminary MEG results have provided valuable insights into the neural mechanisms underlying language processing in Bangla. In line with previous studies, we observed activation in the left temporal lobe, but with a slight time difference (173-197 ms) and specifically related to semantic category violation. This reinforces the importance of the left temporal lobe in processing morphological and semantic information during word formation in the language.
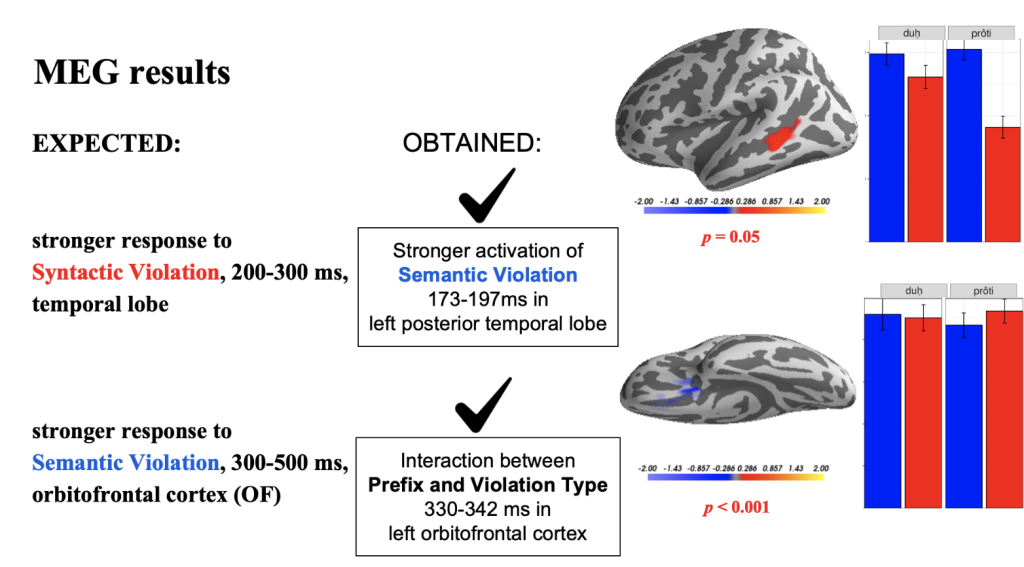
Furthermore, our study has uncovered early activation (330-342 ms) in the orbitofrontal cortex, consistent with other research findings. However, this activation pattern is complex and requires further investigation to fully understand its implications on language processing in Bangla.